
原文地址: https://medium.com/netflix-techblog/vmaf-the-journey-continues-44b51ee9ed12
本文是 Netflix 关于自家的 VMAF(Video Multi-method Assessment Fusion) 的介绍,它可以很好的去评估一个视频的质量通过借助人类视觉模型以及机器学习,它目前已经开源,并且集成在诸如 ffmpeg 这些第三方工具上。
by Zhi Li, Christos Bampis, Julie Novak, Anne Aaron, Kyle Swanson, Anush Moorthy and Jan De Cock
-
Netlfix 是如何评估一个视频的质量的?
-
哪种视频的编码方式更好? Codec A 或者 Codec B?
-
对于这个剧集,1000 kbps 是否比 HD 分辨率更好,或者 SD(标清) 更好?
当我在从事提升 Netflix 播放体验项目时候,这些一直是自己经常问自己的常见问题。很多年前,我们很难回答这些问题,依靠人们肉眼直觉判断。专业的视觉评估并不足够横跨内容,编码实现,以及上面编码流程中。我们可以尝试部署比较常规的观测指标,PSNR 或者 SSIM,但是它们确并不能很好反馈人们视觉的感觉。于是我们开启了这一趟旅程,去开发实现一套自动化回答上述问题的方法。这就是 VMAF 的来缘。
VMAF)是一种视频质量指标,将人类视觉建模与机器学习相结合。该项目开始于我们的团队与 南加州大学 C.-C Jay Kuo 教授之间的研究合作。他的研究小组以前从事图像感知指标的研究,并且我们一起致力于将想法扩展到视频。随着时间的推移,我们已经与其他研究合作伙伴进行了合作,例如德克萨斯大学奥斯汀分校的Alan Bovik教授和南特大学的Patrick Le Callet教授,旨在提高与人类主观感知有关的 VMAF 准确性,并扩大其范围涵盖更多用例。2016年6月,我们在Github上开源了 VMAF,并发布了第一个 VMAF 技术博客。在这篇博文中,我们希望分享我们的旅程。
行业实践
在Netflix之外,视频社区发现VMAF是质量评估的宝贵工具。由于行业的采用,该项目受益于研究人员,视频相关公司和开源社区的广泛贡献。
VMAF已集成到第三方视频分析工具(例如 FFmpeg,Elecard StreamEye, MSU Video Quality Measurement Tool和 arewecompressedyet中,并拥有与更成熟的指标(如PSNR和SSIM)成为一样的地位。
在诸如NAB,Video @ Scale和Demuxed之类的行业贸易展览会和聚会中,使用 VMAF 得分进行演示和演示,以比较各种编码技术的质量和效率。
该视频质量专家组(VQEG)是视频质量评价专家组成的国际财团。在最近的洛斯加托斯,克拉科夫和马德里 VQEG会议上,对VMAF进行了多次讨论。我们很高兴看到其他研究小组对VMAF的感知准确性进行了交叉验证。Rassool(RealNetworks)报告了4K内容的 VMAF 和 DMOS 得分之间的高度相关性。Barman等人(Kingston University)测试了游戏内容的多个质量评估指标,并得出结论,VMAF 是预测主观分数的最佳方法。Lee等人(延世大学)将质量指标应用于多分辨率自适应流式传输,并显示 VMAF 和 EPSNR 与感知质量的相关性最高。在Gutiérrez等人的研究中,VMAF 和 VQM 是表现最好的质量指标。(南特大学),其中为高清和超高清内容生成了 MOS 分数。我们还阅读了一些声称 VMAF 不能达到预期效果的研究。我们邀请行业和研究人员评估最新的 VMAF 模型,并鼓励他们与我们分享可能会改进下一版VMAF的反例和极端案例。我们还将在后面的部分中提供使用VMAF的最佳实践,以解决一些问题。
VMAF可以用作优化准则,以获得更好的编码决策,并且我们已经看到其他公司为此目的应用VMAF的报告。
VMAF 在 Netflix 的实践
编解码器比较
传统上,编解码器比较使用相同的方法:针对多个视频序列计算 PSNR 值,每个视频序列均根据一组测试条件以预定义的分辨率和固定的量化设置进行编码。随后,构建速率质量曲线,并计算这些曲线之间的平均差(BD速率)。这种设置适用于编解码器中的细微差异,或用于同一编解码器中的评估工具。对于我们的用例 Video Streaming,PSNR 的使用是不合适的,因为它与感知质量之间的关联很差。
VMAF 填补了空白,并可以更好地与感知质量相关联的方式捕获编解码器之间的较大差异以及缩放产出。它使我们能够比较真正相关的区域中的编解码器,即在可获得速率质量点的凸包上。比较不同编解码器和/或不同配置之间的凸包,可以比较两个选项在实际重要的速率质量区域中的 Pareto 前沿。我们团队最近在编解码器比较方面的一些工作发表在 技术博客, Optimized shot-based encodes:
Now Streaming!上,并在 2018年图片编码研讨会 和 数字图像处理XLI的SPIE应用程序的学术论文 中发表。
编码决策
VMAF被用于我们的整个生产流程中,不仅可以测量编码过程的结果,还可以指导编码达到最佳质量。在我们的动态优化器中,有一个关于如何在编码中使用VMAF的重要示例 Dynamic Optimizer,其中,每镜头的编码决策由每个编码器选项的比特率和质量测量确定。在优化过程中,VMAF 分数对于获取准确的质量测量以及选择 凸壳上的最终分辨率/比特率点至关重要。
A / B 测试
不同业务领域的研究人员(例如电视UI团队和流媒体客户端团队)正在不断创新以提高流媒体质量。借助VMAF,我们拥有一个工具,可让我们运行系统范围的 A / B 测试去量化对会员视频质量的影响。例如,研究人员更改了自适应流算法或部署了 新的编码,进行了实验,并比较了新算法或旧算法之间的 VMAF。由于该指标在内容上的一致性和反映人类对质量的感知的准确性,因此非常适合评估实验质量。例如,与使用比特率相反,VMAF 分数为 85 表示所有标题的质量都是“良好”,而相同的比特率可能表示标题之间的质量不同。
一直所努力的方向
速度优化
当我们于2016年6月在 Github 上首次发布VMAF时,它的核心特征提取库是用 C 编写的,而控制代码则是用 Python 编写的,其主要目的是支持算法实验和快速原型设计。根据用户的要求,我们很快添加了一个独立的 C ++ 可执行文件,可以在生产环境中更轻松地对其进行部署。2016年12月,我们在 VMAF 的卷积函数中添加了AVX优化,这是VMAF中计算量最大的操作。这使VMAF的执行时间加快了约3倍。最近一次是在2018年6月,我们添加了帧级多线程功能,这是一项长期功能(感谢DonTequila)。我们还介绍了跳帧功能,允许对 N 个帧中的每一个都进行 VMAF 计算。这是首次可以实时计算 VMAF,甚至在 4K 情况下也是如此,尽管准确性会有所降低。
libvmaf
在 FFmpeg 社区的帮助下,我们将 VMAF 打包到一个名为libvmaf的C库中。该库提供了一个接口,可将VMAF测量值合并到您的C / C ++代码中。VMAF 现在已包含在FFmpeg 中作为 过滤器。FFmpeg libvmaf 过滤器易于使用,用于在作为输入的压缩视频比特流上运行 VMAF。
精度提升
自从我们将 VMAF 开源以来,我们一直在不断提高其预测准确性。随着时间的流逝,我们修复了在基本指标和机器学习模型中发现的许多不良情况,从而总体上产生了更准确的预测。例如,对基本度量进行修改以提高亮度掩膜的一致性;更新场景边界处的运动得分,以避免由于场景变化而引起的过冲;现在,当推断到高 QP 区域时,QP-VMAF 的单调性得以保持。显然,VMAF 模型的准确性还很大程度上取决于其所训练的主观分数的覆盖范围和准确性。与以前的数据集相比,我们已经收集了一个范围更广的主观数据集,其中包括内容更加丰富和源伪影,例如胶片颗粒和相机噪点,以及对编码分辨率和压缩参数的更全面介绍。我们还开发了一种新的数据清理技术,可从原始数据中消除人为偏差和不一致之处,并将其开源到Github上。新方法使用最大似然估计,根据可用信息共同优化其参数,从而消除了明确拒绝主题的需要。
查看条件适应
VMAF 框架允许训练针对特定观看条件量身定制的预测模型,无论是在手机上还是在 UHD 电视上。当我们将VMAF 开源时发布的原始模型是基于这样的假设:观看者坐在类似客厅的环境中的1080p显示器前面,观看距离是屏幕高度(3H)的3倍。此设置通常对许多情况有用。但是,在将此模型应用于手机观看时,我们发现它无法准确反映观看者对手机质量的看法。尤其是,由于屏幕尺寸较小且相对于屏幕高度(> 3H)的观看距离更长,观众可以观看到质量差异较小的高质量视频。例如,在手机上,与其他设备相比,720p 和 1080p 视频之间的区别较小。考虑到这一点,我们训练并发布了VMAF 移动端模型。
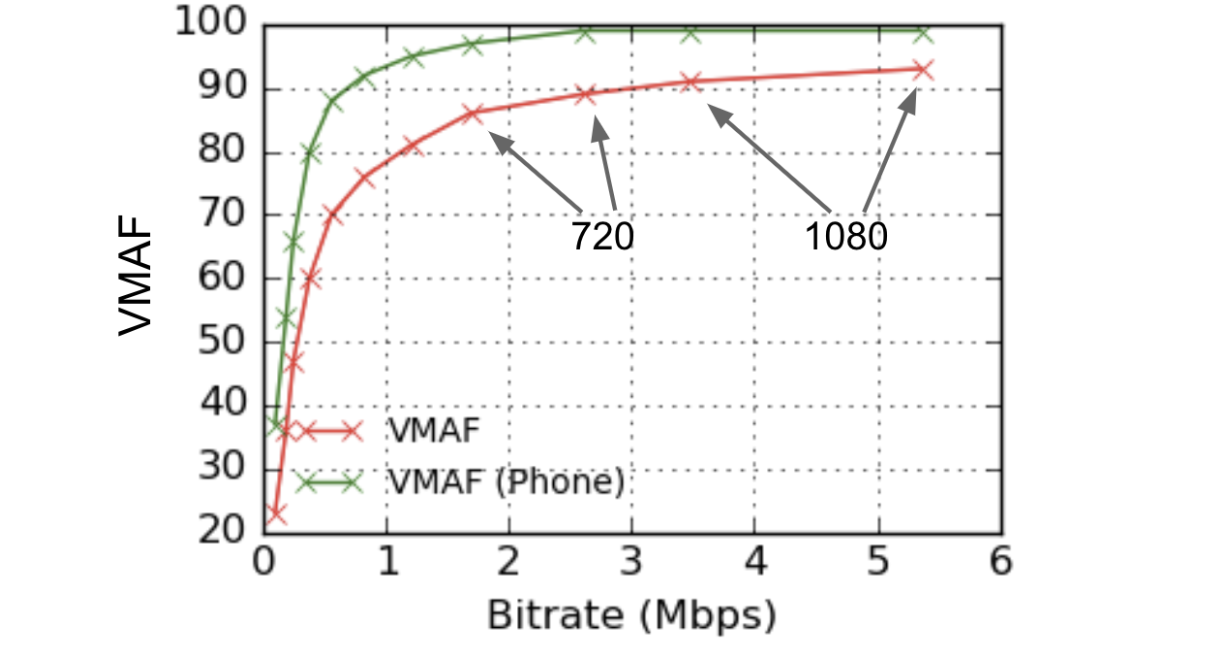
上面显示了默认模型和电话模型的示例VMAF-比特率关系。可以解释为,在手机屏幕上观看时,相同的失真视频将被认为具有比高清电视更高的质量,并且使用手机型号,720p 和 1080p 视频之间的 VMAF 得分差异较小。
最近,我们添加了一个新的 4K VMAF 模型,该模型可以预测在 4K 电视上显示并从 1.5H 距离观看的视频的主观质量。1.5H 的观看距离是普通观看者欣赏4K内容清晰度的最大距离。4K模型与默认模型相似,因为这两个模型均以 1/60 度/像素的临界角频率捕获质量。但是,4K 模型假定视角较宽,这会影响对象使用的中央凹与周围视觉。
量化预测不确定性
对 VMAF 进行了一系列代表性视频流派和失真的训练。由于基于实验室的主观实验的规模有限,视频序列的选择不能涵盖感知视频质量的整个空间。因此,VMAF 预测需要与表示训练过程固有不确定性的置信区间(CI)相关联。为此,我们最近推出了一种方法,可将 VMAF预测得分与 95% CI 相伴随,从而量化了预测位于区间内的置信度。通过引导预测残差建立 CI 使用完整的训练数据。本质上,它使用 “替换后重采样” 对预测残差训练多个模型。每个模型都会引入略有不同的预测。这些预测的可变性量化了置信度-这些预测越接近,使用完整数据进行的预测就越可靠。
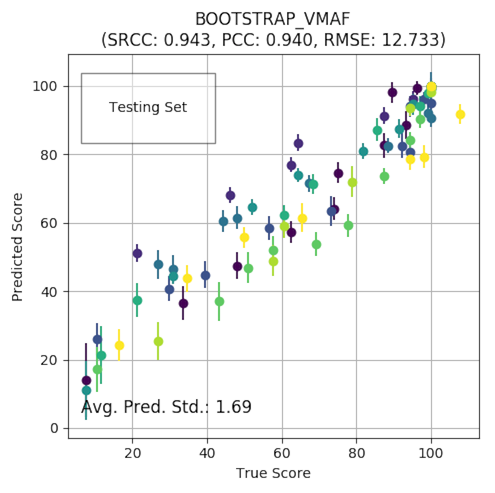
上面基于 NFLX公共数据集的示例图展示了与每个数据点关联的95%CI。有趣的是,得分较高的一端的 CI 往往比得分较低的一端的 CI 更严格。这可以通过以下事实来解释:在训练VMAF模型的数据集中,较高端的数据点多于较低端的数据点。值得注意的是,自举技术不一定会提高训练模型的准确性,但会为其预测提供统计意义。
最佳实践
通常,我们被问到一种特定的计算 VMAF 分数的方法是否合适,或者如何解释获得的分数。本节重点介绍了使用 VMAF 的一些最佳实践。
VMAF分数解释
VMAF分数范围从 0 到 100,其中 0 表示最低质量,100表示最高。思考VMAF分数的一种好方法是将其线性映射到人的意见量表,在此条件下可获得训练分数。例如,默认模型 v0.6.1 使用由绝对类别评分(ACR)方法收集的分数进行训练,该分数使用 1080p 显示屏,观看距离为3H。观看者对视频质量的评分为“差”,“差”,“一般”,“好”和“优秀”,并且粗略地讲,“差”被映射为VMAF级别20,“优秀”为100。因此,VMAF得分70可以被普通观众理解为在 1080p 和 3H 条件下的“好”和“一般”之间的投票。要考虑的另一个因素是,观看者可以给出的最佳和最差选票是通过整套视频中质量最高和最低的视频进行校准的(在训练过程中以及在实际测试开始之前,受试者通常习惯于实验的规模) )。在默认模型 v0.6.1 的情况下,最佳视频和最差视频分别是在量化参数(QP)低的1080p下压缩和在QP 高的 240p下压缩的视频。
以正确的分辨率计算VMAF
用于自适应流传输的典型编码管道会引入两种类型的伪像-压缩伪像(由于有损压缩)和缩放伪像(对于低比特率,在压缩之前先对源视频进行下采样,然后在显示设备上进行上采样)。在使用VMAF评估感知质量时,必须同时考虑两种伪像。例如,当一个信号源是1080p但编码是480p时,在该对上计算VMAF的正确方法是将编码上采样到1080p以匹配该信号源的分辨率。相反,如果将源下采样到480p以匹配编码,则获得的VMAF分数将无法捕获缩放伪像。当使用VMAF作为每标题编码的质量标准时,这一点尤其重要,其中凸包的构造对于选择最佳编码参数至关重要。

上面的示例说明了正确(左)和错误(右)计算 VMAF时形成的凸包。通过对VMAF进行上采样编码以匹配源分辨率来计算VMAF时,可以轻松识别出具有不同分辨率的曲线之间的交点。另一方面,如果对源进行下采样以匹配编码分辨率,则低分辨率编码将产生不必要的高分,并且曲线之间的交集模式也无法发现。
选择一个上采样算法
在对编码进行上采样以匹配源分辨率时,可以使用许多上采样算法,包括bilinear,bicubic,lanczos,甚至是更高级的基于神经网络的方法。确实,上采样算法的质量越高越好。原则上,应该选择一种最能匹配显示设备的算法。在许多情况下,在显示器中对视频进行上采样的精确电路是未知的。在这种情况下,我们建议一般使用双三次上采样作为近似值。
当分辨率不是 1080p 时解释 VMAF 得分
一个常见问题是:如果源视频和编码视频的分辨率都低于1080p,那么1080p模型(例如默认模型 v0.6.1)是否仍然适用?请注意,默认模型在 1/60 [度/像素] 的临界角频率下测量质量。考虑默认模型的一种方法是,它是“ 1/60 [度/像素] ”模型,这意味着它假定将60个像素打包成一个视角。如果应用几何图形,人们会发现它同样适用于 3H 的 1080p 视频,4.5H 的 720p 视频或 6.75H 的 480p 视频。换句话说,如果将 1080p 模型应用于 720p / 480p 视频,则所得的分数可以分别解释为以 4.5H / 6.75H 的观看距离获得的分数。在这么长的观看距离下,人眼看不见许多伪像,
请注意,这种解释没有校准其他因素,例如眼睛焦距,中央凹视力以及观众对 SD 和 HD 视频的期望。
时间池
VMAF 每视频帧产生一个分数。通常,对于较长的持续时间(例如,几秒钟的视频片段或什至两小时的电影)生成摘要分数通常很有用。尽管存在先进的技术来暂时合并每帧得分,但我们的经验结果表明,简单算术平均值(AM)是最好的平均方式,因为它与主观得分的相关性最高。
另一种有用的平均技术是谐波均值(HM)。通常情况下,它会产生与 AM 非常相似的汇总评分,除了在存在异常值的情况下,HM 强调小数值的影响。
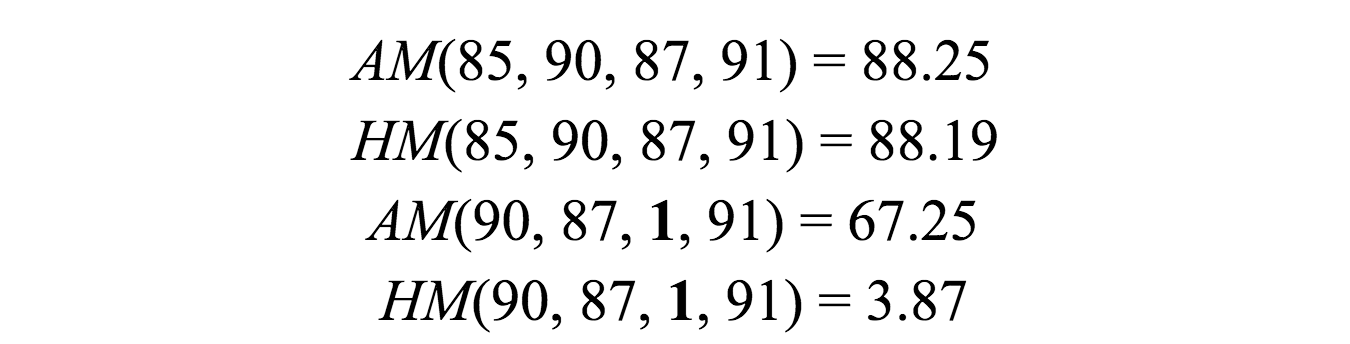
以上示例说明了在不存在/存在小数值离群值的情况下AM / HM 之间的差异。当人们希望基于 VMAF 优化质量同时避免偶发的低质量视频编码时,基于 HM 的时间池很有用。
A / B实验指标
为了了解A / B测试中不同处理的效果,我们需要度量标准以将每帧 VMAF 分数汇总为每个会话度量标准(即,每个会话一个数字)。更为严峻的是,由于在自适应流传输中,基于各种因素(例如吞吐量)选择了要传输的最佳比特率,因此,基于每个流的持续时间,每个会话将具有不同的每帧 VMAF 值“组合”在该时段的播放期间播放。为了在每个会话中获得单个 VMAF 摘要编号,我们必须
1)确定适当的聚合级别
2)在这些聚合的基础上建立反映感知质量不同方面的指标。
如果将每帧 VMAF 分数汇总为每个流一个平均值,我们将错过会话期间发生的质量下降。如果我们根本不进行汇总,而是使用每帧值,那么基于每次会话的每帧值创建最终摘要指标的计算复杂度将太高。为此,我们建议间隔几秒钟的间隔,以在分析准确性和易于实现之间取得平衡。
为了了解A / B测试中不同处理方式的影响,我们建议使用可捕获质量三个关键方面的指标:聚合质量,开始播放质量和可变性。这些可能是整个会话的平均 VMAF,前 N秒 的平均 VMAF,以及相对于先前值,VMAF 值下降到某个阈值以下的次数。
旅程继续
从帮助向 Netflix 用户提供最佳视频质量的内部项目,到开始吸引用户和贡献者社区的开源项目,VMAF 一直在不断发展并不断寻找新的应用领域。我们很高兴看到在 Netflix 内部和外部,VMAF 已被应用于编解码器比较,编码优化,A / B 实验,视频分析,后处理优化以及更多领域。独立研究人员已经帮助交叉验证了 VMAF 的感知准确性。开源社区帮助加快了该工具的速度,创建了易于使用的界面,并管理 Github。
但是我们才刚刚开始。
通过与研究人员和 VMAF 采纳者的对话,我们意识到当前 VMAF 可以在很多方面进行改进。举几个例子:
-
VMAF 使用简单的时间特征,即相邻帧之间的平均低通滤波后的差异。VMAF 可能会受益于更复杂的模型,该模型可以更好地测量时间感官效应。
-
尽管与 PSNR 相比,VMAF朝着正确的方向发展,但VMAF并未完全抓住许多编解码器中感知优化选项的优势。
-
当前,VMAF不使用色度功能,并且不能完全表达HDR / WCG 视频的感知优势。
-
VMAF模型在几秒钟的视频中效果最佳。它不会捕获长期影响,例如新近度和优先级以及重新缓冲事件。
在未来的几年中,我们努力继续改进VMAF,并邀请行业,学术界和开源社区与我们合作。
致谢
在此感谢以下个人在VMAF项目中的帮助:C.-C Jay Kuo教授(南加州大学),Joe Yuchieh Lin,Eddy Chi-Hao Wu,Wang Haiqiang Wang,Patrick Le Callet 教授(南特大学),Jing Li,Yoann Baveye,Lukas Krasula,Alan Bovik 教授(德克萨斯大学奥斯汀分校),Todd Goodall,Ioannis Katsavounidis,视频算法团队成员,Streaming S&A 的 Martin Tingley 和 Lavanya Sharan以及 VMAF 项目的开源贡献者。