
之前写过了语音合成,即是进行文字发音,当然现在也支持了语音识别,
即将你所说的转化成文字。Chrome 浏览器在版本25之后开始对这一特性的支持。
基础用法
var recognition = new webkitSpeechRecognition();
recognition.onresult = function(event) {
console.log(event)
}
recognition.start();
这里操作实际会让用户授权页面开启麦克风,如果用户允许的话,用户可以开始说话了,如果你停说话了,onresult注册的时间
则会被触发,并会讲捕获的音频返回成一个JavaScript对象。
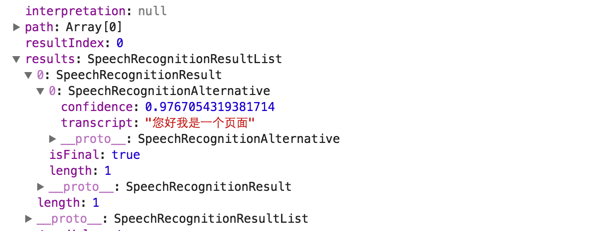
响应流
你需要等待用户准备好对话,并且知道对话结束;
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onresult = function(event) {
console.log(event)
}
recognition.start();
这样你可以在用户开始讲话时,提前渲染结果。
你可以自动以识别的语言,默认情况为所在地区语言。
x-webkit-speech
Webkit 内核的浏览器支持语音输入
<input type="text" x-webkit-speech />
它会识别音频并进行转化为文字
安全性
http协议下浏览器每次都会提醒用户去确认语音操作,然而https的页面,没有这样一个麻烦的操作。
JavaScript上下文,整个页面,都能过访问到捕获的音频。
小结
JavaScript的语音识别总体还并未大范围使用,而且受限于浏览器支持,因此只有少数需求或许能够使用到把。